总体概述 #
使用场景 #
Kafka 在搜索服务、直播服务、订单服务和支付服务等都有涉及,这些服务产生的日志信息,其 Metrics 数据,即 CPU 利用率、内存利用率等信息,以及用户的行为,都会使用 Kafka 消息队列。
如何使用 Kafka #
- 首先需要创建集群,一般来说对于公司而言已经搭建起了一个 kafka 集群,直接使用即可;
- 随后用户新建一个 topic ,并且设置好分片数量
- 引入相对应语言的 SDK,配置好集群和 Topic 等参数,初始化一个生产者,调用 Send 方法,将你的消息发送出去
- 引入相对应语言的 SDK,配置好集群和 Topic 等参数,初始化一个消费者,调用 Poll 方法,接受发送过来的消息 ![[Kafka 2023-02-11 12.51.24.excalidraw]]
基本概念 #
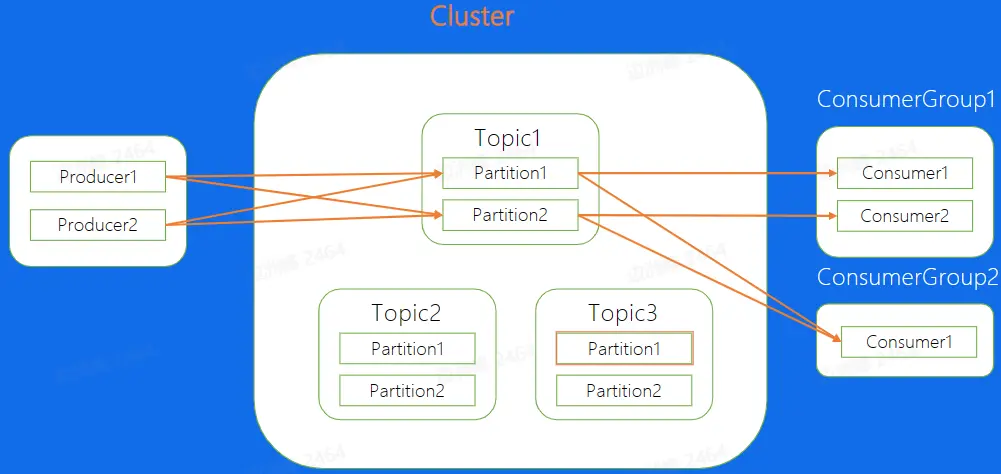
- Topic: 逻辑队列,不同的业务场景使用不同的 topic,对于某一个业务而言,所有消息都存在一个 topic 中
- 一个 Topic 中可以包含多个 Partition,即分片,不同的分片之间的消息是可以并发处理的,从而提高了处理消息的能力。
- Cluster: 物理集群,每个集群中可以建立多个不同的 Topic
- Producer: 生产者,负责将业务消息发送到 Topic 中
- Consumer: 消费者,负责消费已经发放到 topic 中的数据
- ConsumerGroup: 消费者组,不同组 Consumer 消费进度互不干涉
Topic 内部 #
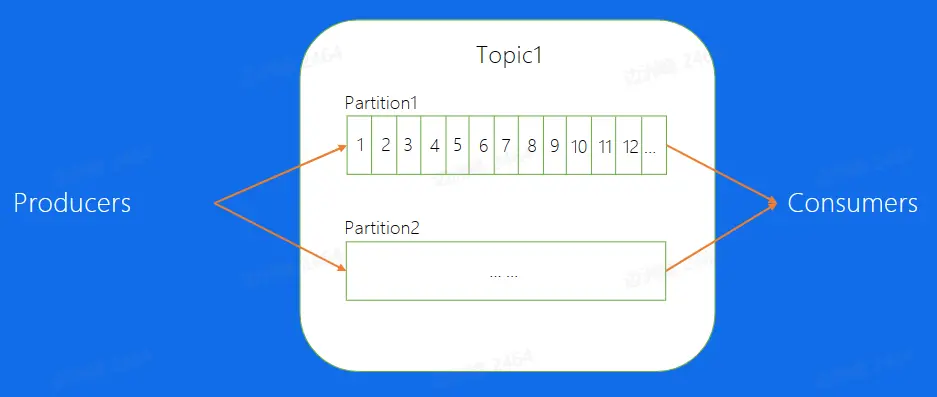
Topic 包含多个分片,每一个分片为正式存储消息的数据结构,其中 Partition 中的消息使用 Offset 表示其在内部的相对位置,可以理解为唯一 ID,并且在 Partition 内部是严格递增的。
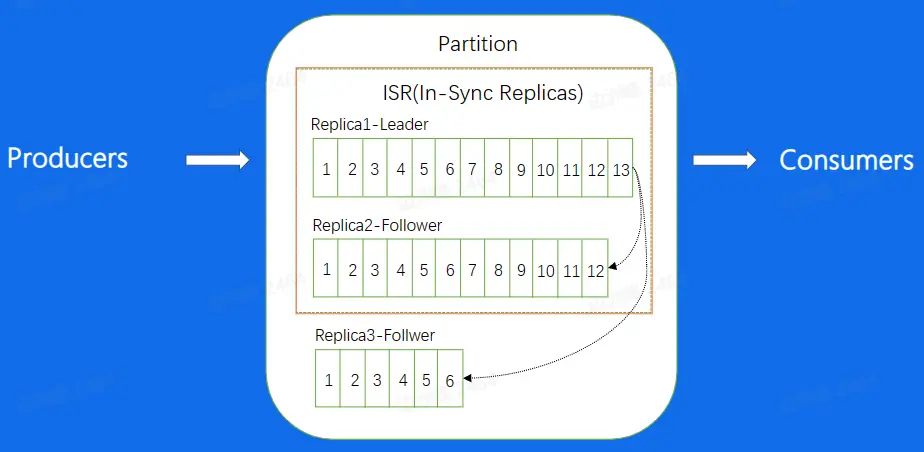
由于不用服务器之间的物理差异,不同的 Follower 拉取副本的能力也有不同,且他们与 Leader 的差距总是存在的。为了保证容灾后消息差异不是很大,需要配置 ISR(In-Sync Replicas)的参数,当 Follower 与 Leader 在 ISR 配置范围内时,则将其加入 ISR 中,否则就将其排除在外,不在 ISR 中的 Follower 是不可以升级成为 Leader 的。
ISR 的配置在老的版本是由 Offest 差异数来定义的,目前是由时间差异定义。
Kafka 架构设计 #
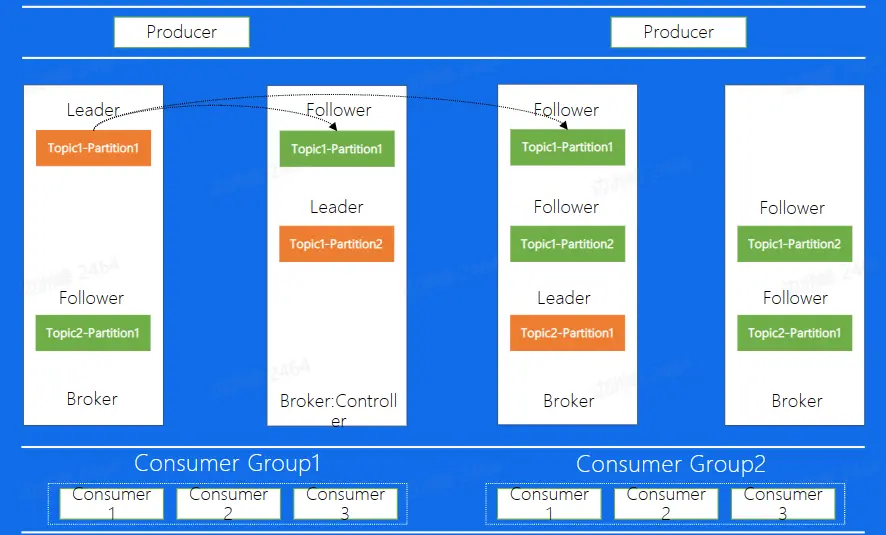
Kafka 集群的整体结构如下,broker 为每一个 Kafka 的节点,所有的 Broker 最终组成了一个集群。在图中包含了 4 个 broker 节点,集群中有两个 topic,其中 topic1 有两个分区,topic2 只有 1 个分区;在四个 broker 中第二个 Broker 扮演着 Controller 的身份,其为整个集群的大脑,负责副本和 Broker 的分配。
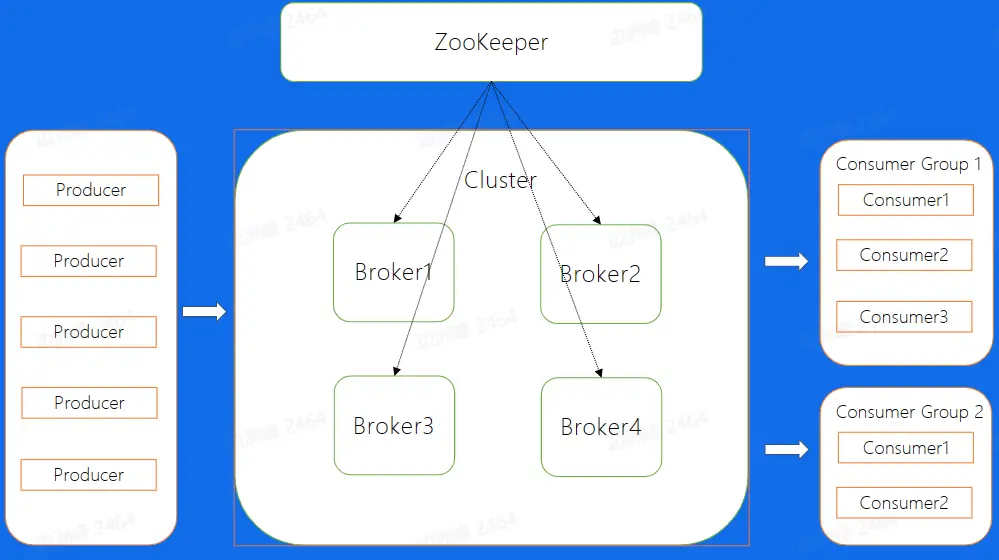
消息传递原理 #
一条消息在整个集群中经过以下的路径完成他的生命周期:由 Producer 生产出消息后,将消息放置到 Broker 中,随后 Consumer 将其消费。 ![[Kafka 2023-02-11 16.32.38.excalidraw]]
Producer #
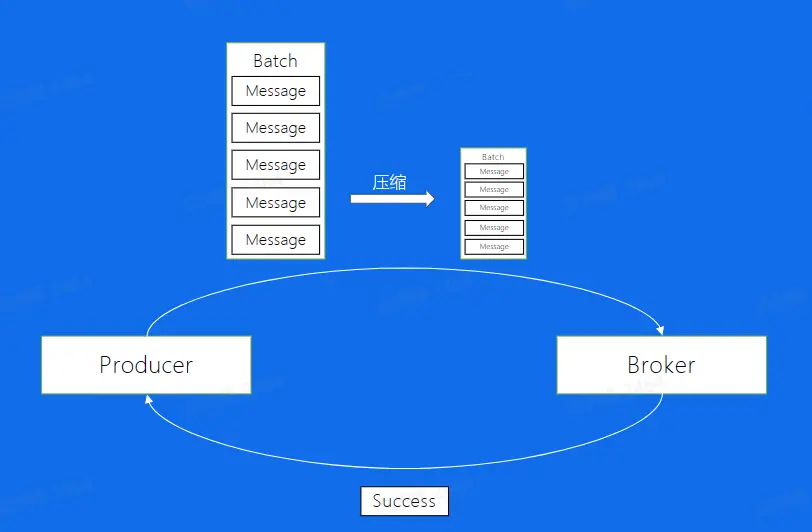
Producer 主要负责将消息发送给 Broker,Producer 发送一条数据后 Broker 返回一个 Success 信息。假设消息是一条一条发送给 Broker 的,除去数据传输的时间,启动 IO 次数过多,操作将会消耗比较多的时间,无法实现非常高的吞吐量。所以 Kafka 实现了批量发送数据,将生产的多个数据合并在一起 Batch 中,如此可以减少 IO 次数,从而加强发送能力。
另外一个 Batch 中的数据往往是比较大的,为了减小带宽的压力,Kafka 通过压缩,减小了消息的大小,相同的带宽可以承受的消息大小更大了,目前支持的压缩算法有:Snappy、Gzip、LZ4、ZSTD,其中 Snappy 是默认的算法,而根据实践得到,ZSTD 的效果更加。
Broker #
消息文件结构 #
在每个 Broker 中,都分布着不同 topic 的不同分片,分片在不同 Broker 中存储的副本的文件结构如下图所示。该文件结构下,数据的路径为 /Topic/Partition/Segment/(log | index | timeindex |...。
Producer 生产出来的消息被存放在 log 中,每一个 log 文件会被分为多个分区,每个分区有主要有三个文件来存储,分别是:
- .log 日志文件:该文件为消息的本体,消息的数据存放在该文件中。
- .index 偏移量索引文件:该文件存放消息在日志文件中的索引信息。
- . timeindex 时间戳索引文件:该文件存放使用时间戳的方式进行日志文件索引的索引信息。 以上的文件的命名为该分区 log 中第一条消息的 offset 值。
以上的文件的读写会消耗大量 IO 时间,而根据 [[磁盘#磁盘基本情况|磁盘]] 的读取时间大部分来源于寻道时间,为了实现高吞吐量,在写入文件时需要尽量减少寻道时间,即在新增加一条消息是在末尾追加写,即顺序写入,而不是像数据库一样实现随机写。
如何寻找消息 #
Consumer 通过 FetchRequest 请求消息数据,Broker 会将制定 offset 出的消息按照时间窗口和消息消息大小发送给 Consumer。Broker 需要从日志文件中找到该 offset 对应的消息,寻找消息需要走两步:首先在分区中寻找消息所在的 log 分片,随后在该分片中寻找其位置即可,以下为具体的流程:
-
拿到消息所在的 offset 后,使用二分找到小于目标 Offset 的最大分区。比如下图中,如果需要找 28 偏移则需要在
6.log分区查找其消息位置。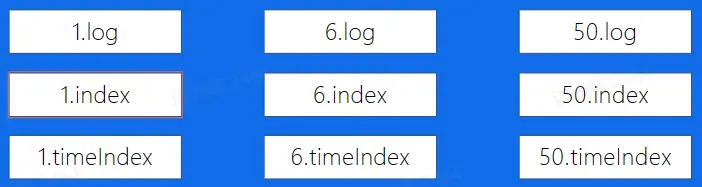
-
在分区中有两种索引的方式的文件:
- 偏移量索引:此处使用[[稀疏索引]]的方式,即索引条目中只有一些搜索键值,并不是所有搜索键值,首先二分找到小于目标 offset 的最大索引,根据其在 log 文件中的文件偏移读取记录,因为所读取的消息不一定就在该位置,所以需要顺序读该位置之后的 batch,直到读到目标 offset 后结束。
- 时间戳索引:如果我们需要使用时间戳来寻找的时候,和 offset 相比只是多加了以及索引,也就是通过二分找到时间戳对应的 offset,再重复之前的步骤找到相应的文件数据。
数据拷贝 #
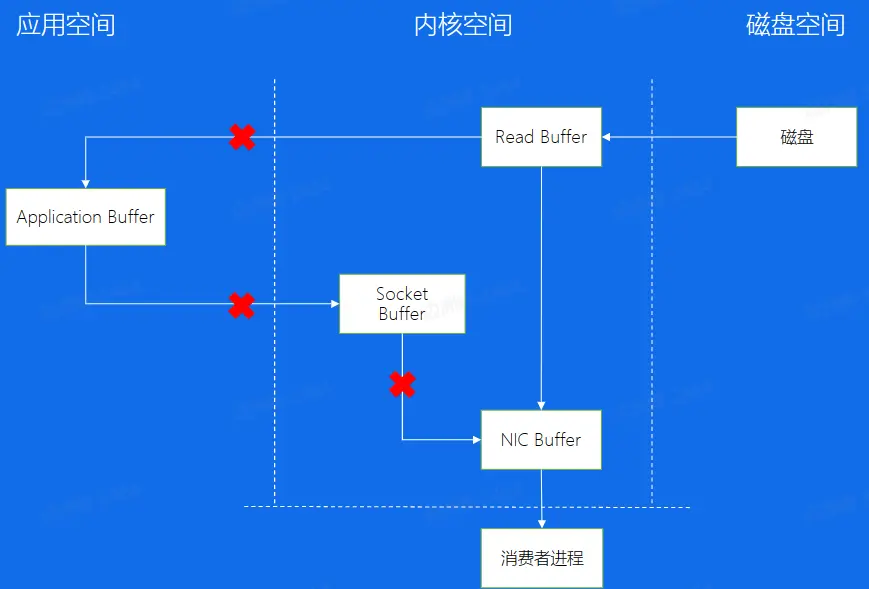
将操作系统可以简单的分为用户空间、内核空间,在操作系统之外有外存:磁盘,日志文件都存放在磁盘中,消费这些日志文件需要从磁盘复制到消费者进程中,对于的传统拷贝来说,数据需要从磁盘先读入内核空间的 ReadBuffer,再复制到用户空间中的 Application Buffer,随后又进入内核空间,通过 Socket Buffer 和 NIC Buffer 将数据拷贝到消费者进程。为了减少内核的切换和数据拷贝的次数,Kafka 会使用零拷贝的技术,使用 sendfile 系统调用在内核空间中就把数据从 Read Buffer 拷贝到 NIC Reader 中,以供消费者进程消费。
此处的应用为磁盘与其他计算机的通信,其跳过了应用空间,而对于两台计算机之间的应用进程通信,比如客户端和服务端,也用了类似的思想,即 [[RDMA]],跳过了内核空间直接与对面的应用进程通信 深入浅出全面解析RDMA
Consumer #
对于一个 Consumer Group 来说,多个分片可以并发的消费,这样可以大大提高消费的效率,但需要解决的问题是,Consumer 和 Partition 的分配问题,也就是对于每一个 Partition 来讲,该由哪一个 Consumer 来消费的问题。对于这个问题,我们一般有两种解决方法,手动分配和自动分配:
手动分配(low level) #
手动分配,也就是 Kafka 中所说的 Low Level 消费方式进行消费,这种分配方式的一个好处就是启动比较快,因为对于每一个 Consumer 来说,启动的时候就已经知道了自己应该去消费哪个消费方式,就好比图中的 Consumer Group1 来说,Consumer1 去消费 Partition1, 2, 3 Consumer2,去消费 456, Consumer3 去消费 78。这些消费者在启动的时候就知道了分配的方案了,但是这种方案会出现断流,主要有以下两个情况:
- 当有一个 Consumer 挂掉了,那么就会出现其负责消费的分区的流量出现断流。
- 另外一种情况,如果需要增加一个新的 Consumer,需要把整个集群都停掉,新增一个 Consumer 的配置。 这种情况出现的断流对于业务来说是一个致命的问题,所以需要使用比较高级分配方式。
自动分配(high level) #
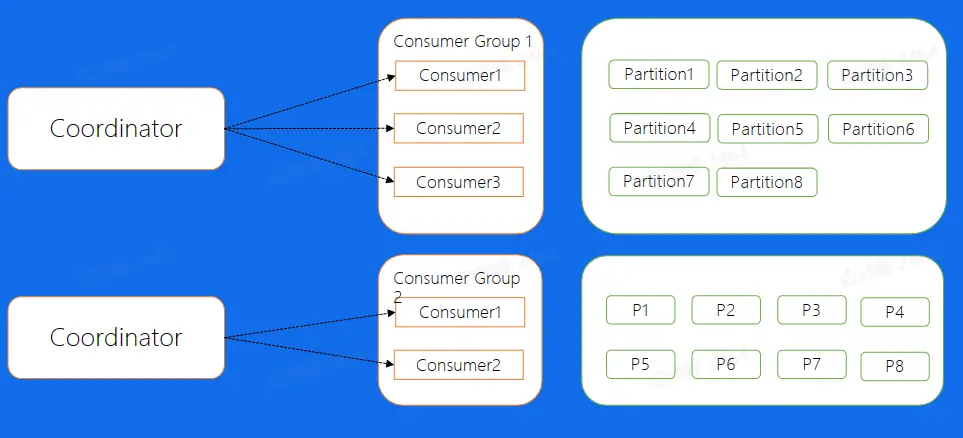
Kafka 提供了自动分配的方式,这里也叫做 High Level 的消费方式,简单的来说,就是在我们的 Broker 集群中,对于不同的 Consumer Group 来讲,都会选取一台 Broker 当做 Coordinator,而 Coordinator 的作用就是帮助 Consumer Group 进行分片的分配,也叫做分片的 rebalance,使用这种方式,如果 ConsumerGroup 中有发生宕机,或者有新的 Consumer 加入,整个 partition 和 Consumer 都会重新进行分配来达到一个稳定的消费状态。
Rebalance 过程 #
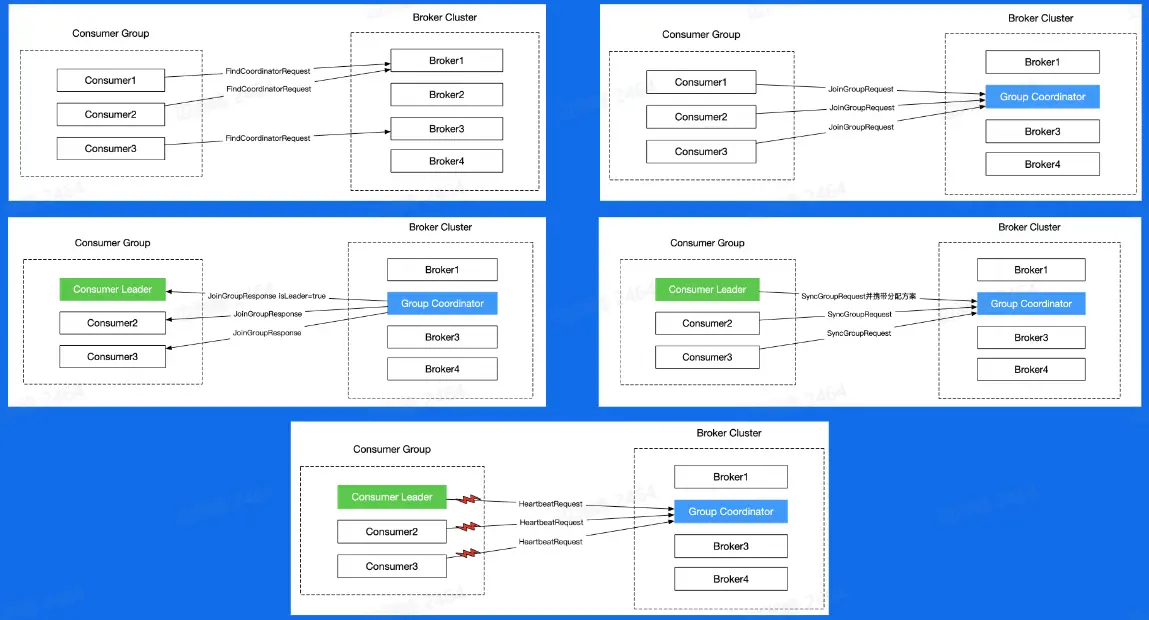
- 首先所有的 Consumer 随机发送 FindCoordinatorRequest 请求,Broker 集群会根据负载均衡的情况提供 Coordinator 的 Broker 编号
- 根据 Broker 号,Consumer 发送 JoinGroupRequest 请求给 Coordinator,以让当前请求的 Coordinator 担任当前消费组的协调者。
- Coordinator 响应 Join 请求,并发送给当前组的第一个消费者
isLeader=true参数,表示当前消费者为当前消费组的 Leader,该 Leader 与 Coordinator 通信,交流分配方案。 - Leader 携带分配方案向 Coordinator 发起 SyncGroupRequest 请求,并且其他 Consumer 也发送 SyncGroupRequest 请求,以获取被分配的分区。
- 分配完之后所有的 Consumer 隔一段时间就需要向 Coordinator 发送心跳 HeartBeatRequest,如果检测到有一个 Consumer 出现问题,则会重新开始 Rebalance 流程。
缺陷 #
从前面可以看到,对于 Kafka 来说,每一个 Broker 都有不同 Topic 的副本,而每一个副本存储在 Kafka 节点上面,通过对副本地复制,来保证数据最终的一致性。但是这种方式会带来一定的问题,如下。
重启耗时长 #
假设对一个机器进行重启,假设该 Broker 存在某一个 Topic 的 Leader,那么需要一下几步:
- 首先需要对该 Topic 进行 Leader 切换,切换到在其他节点且在 ISA 中的 Follower 副本
- 此时数据还是不断地在写入,对于刚刚关闭重启的 Broker 来说,和新的 Leader 之间有一定的数据滞后,所以需要花费比较长的时间追赶数据,重新回到 ISA 当中。
- 当数据追赶完毕后,我们需要回切 Leader,将重启的 Broker 变为 Leader,即 Prefer Leader。这一步的目的主要目的是避免,在一个集群长期运行后,所有的 Leader 都分布在少数节点上,导致数据的不平衡。

注意:此处是不能进行并发重启的,假设一个集群中,topic 的分片副本是两个,如果重启的两台机器中刚好存放了两个分片的副本,那么对于该分片来说,就是不可用的状态,是不能接受的。
数据拷贝开销大 #
对于替换、扩容、缩容来说,也会出现类似重启是出现的拷贝开销大的问题。
- 如果是替换,和刚刚的重启有什么区别,其实替换,本质上来讲就是一个需要追更多数据的重启操作,因为正常重启只需要追一小部分,而替换,则是需要复制整个 leader 的数据,时间会更长。
- 扩容:当分片分配到新的机器上以后,也是相当于要从 0 开始复制一些新的副本
- 缩容:缩容节点上面的分片也会分片到集群中剩余节点上面,分配过去的副本也会从 0 开始去复制数据 以上三个操作均有数据复制所带来的时间成本问题,所以对于Kafka来说,运维操作所带来的时间成本是不容忽视的
负载不均衡 #
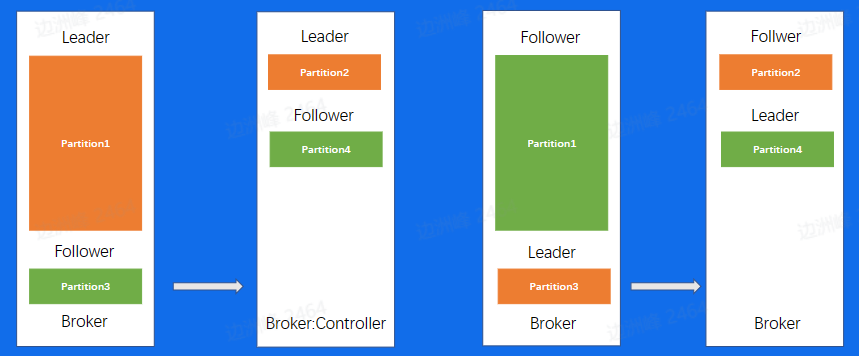
总结 #
从上面的几个问题,可以看出基本上的问题是来自于数据复制,总体来说,会带来以下几个问题:
- 数据复制的时间成本太高,导致运维成本高。
- 对于负载不均衡的场景,需要设计比较复杂的负载均衡机制来权衡 IO 问题。
- Kafka 没有自己的缓存,完全依赖文件系统的 Page Cache,灵活度不够。
- 另外 Controller 和 Coordinator 都是和 Broker 部署在一起的,Controller 负责分片方案,Coordinator 负责 Rebalance 的流程,大量 IO 会造成其性能下降,这回影响集群的可用性。
